Claude ≠ Opus: Demystifying the AI "Chat Harness"
The assistant is not the model. The useful AI product is the orchestrated system around the model.
Here is the secret: Claude is not Opus. ChatGPT is not GPT-5.
In my last article, we explored the Trust Flywheel. We discussed how the next wave of customer experience, the Ambient Era, will require us to hand over unprecedented access to our personal lives, and why we will only grant that access if the AI builds a genuine relationship with us.
But before we jump into that ambient future, let’s ground ourselves in the present.
If we want to understand how an AI will eventually take the chaotic, unstructured context of our lives and actually use it, we first have to look under the hood and address a massive misconception about how AI works today.
The assistant is not the model.
The assistant is the orchestrated system around the model.
Most people use brand names interchangeably, thinking the chat interface they log into is the underlying AI model. It’s not. The AI model itself is just a single component: a brilliant, but entirely stateless, reasoning engine. The magic you experience every day isn’t the model alone. It’s the invisible application wrapped around it.
This is exactly why booting up a raw, local model using tools like Ollama or LM Studio often feels so underwhelming compared to using a flagship commercial assistant. Without a sophisticated architecture to manage memory, context, and external tools, you are just talking to an isolated, amnesiac brain.
We call this architecture the Chat Harness.
The Stateless Brain and the Architecture of Memory
To understand the harness, you must first understand the inherent limitations of the attention transformer architecture that powers models like GPT-5 or Opus 4. By design, they enable scale by remaining stateless.
These models are powerful reasoning engines, but they suffer from profound amnesia. Every single time you send a prompt to an LLM, it wakes up with absolutely zero memory of who you are, what you said three seconds ago, or what you discussed last Tuesday. It is a stateless brain.
So, when you ask your AI assistant to “rewrite that email in a more professional tone,” and it flawlessly remembers the email you were working on yesterday, how is that possible?
The model didn’t remember it. It was handed to it.
Memory isn’t a cognitive function of the model. It’s an architectural feature of the application. The model doesn’t intrinsically remember you. Instead, the Chat Harness acts as an orchestrator that stores and retrieves your past interactions, secretly injecting them into your prompt right before the LLM reads it.
The Blind Brain and the Orchestration of Tools
Memory isn’t the only thing the model lacks. It also lacks a connection to the outside world.
When you ask an AI, “What is the weather in Seattle today?”, the underlying model itself has no inherent ability to check the internet. It is a closed system, frozen in time at the moment its training was completed.
So how does it give you the live forecast? Again, it relies on the Chat Harness.
When the orchestrator receives your initial prompt, it curates a specific list of tools that it anticipates might be useful, such as a web search tool or a weather API, and passes that list to the LLM.
The LLM was trained to look at this list and determine if any of these tools would help answer the prompt. If the LLM determines that a tool result is needed to complete a response, it responds back to the harness with a request to run a tool and return the results.
The model didn’t browse the web. It recognized that it needed to and directed the harness to make the call. The model then read the summary that it requested as part of an augmented context.
Demystifying the Chat Harness
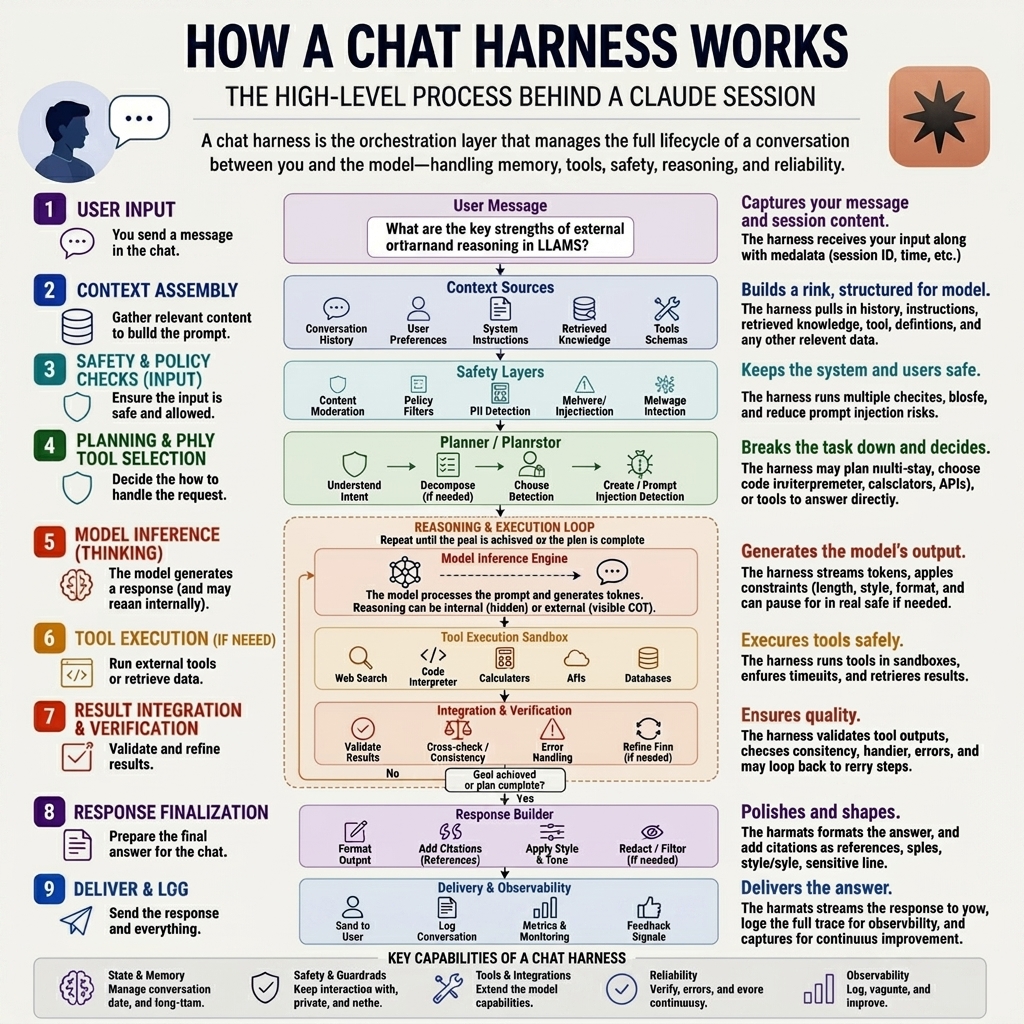
To make an isolated, stateless brain useful, you have to build an architecture around it that handles memory, instructions, and actions. This is the Chat Harness.
When you type a message to an AI, your text doesn’t go straight to the model. It goes through a sophisticated pipeline:
- User input: You type your request into the chat interface.
- Context assembly: The harness gathers everything needed to build the prompt. This includes your conversation history, user preferences, retrieved knowledge such as RAG from a vector database, hidden system instructions, and tool schemas.
- Safety and policy checks: Before moving forward, the harness runs checks such as content moderation, PII detection, and prompt injection filters to ensure the input is safe and allowed.
- Planning and tool selection: The orchestrator analyzes your intent, breaks the task down if necessary, and decides how to handle the request.
- Model inference: The assembled package of context is handed to the stateless brain. The LLM processes the prompt, reasons through it, and generates a response.
- Tool execution: If the model determines it needs external data, the harness executes that tool in a secure sandbox and retrieves the results.
- Result integration and verification: The harness cross-checks the tool outputs for errors or consistency. If something fails, it may loop back to retry the step.
- Response finalization: The harness formats the final answer, applies the correct brand style and tone, adds citations, and runs final redactions if necessary.
- Deliver and log: The completed response streams back to your screen while the harness logs the interaction and captures feedback signals for continuous improvement.
When you look at this pipeline, you realize that context isn’t magical, human-like understanding. Context is structured data injected into the pipeline right before the LLM runs.
Why This Matters for the Ambient Era
Understanding the Chat Harness is the key to understanding the future of AI.
Right now, the data feeding into that pipeline comes mostly from the text you type. But in the Ambient Era, the harness won’t just wait for you to type. It will continuously pull ambient signals: your geolocation, your calendar events, and the camera feed in your room. The AI won’t just answer questions; it will proactively orchestrate your life based on the environment around you.
But there is a massive catch.
Look closely at Step 2 of the pipeline: the vector database. That database is the master record of your entire digital relationship with the AI. It holds your preferences, your history, and soon, your ambient, real-time context.
Currently, that vector database is owned and hosted by massive tech corporations in centralized clouds.
If the future of customer experience requires your AI to have intimate, ambient context of your life to be useful, are you willing to hand all that data over to a centralized corporate database?
Or should your memory belong to you?
What if, instead of a corporate server, your context lived in a sovereign, local vector database? Imagine a future where you own a personal, local agent that acts as a secure firewall. When a third-party brand or app wants to interact with you, their agent must negotiate with your agent, and your agent only grants temporary, strictly permissioned access to your context.
We are moving away from the era of centralized data harvesting and into an era of sovereign context. And that shift will rewrite the rules of digital privacy, marketing, and the internet itself.
Originally published on LinkedIn. View the original post.